RAG Chatbot · Mednova/
A retrieval-augmented chatbot that answers from a healthcare client's internal knowledge base — n8n workflows, Pinecone vector store, OpenAI embeddings, with every conversation logged for evaluation.
Browse the project/
Swipe through the shipped surfaces — one screen at a time.
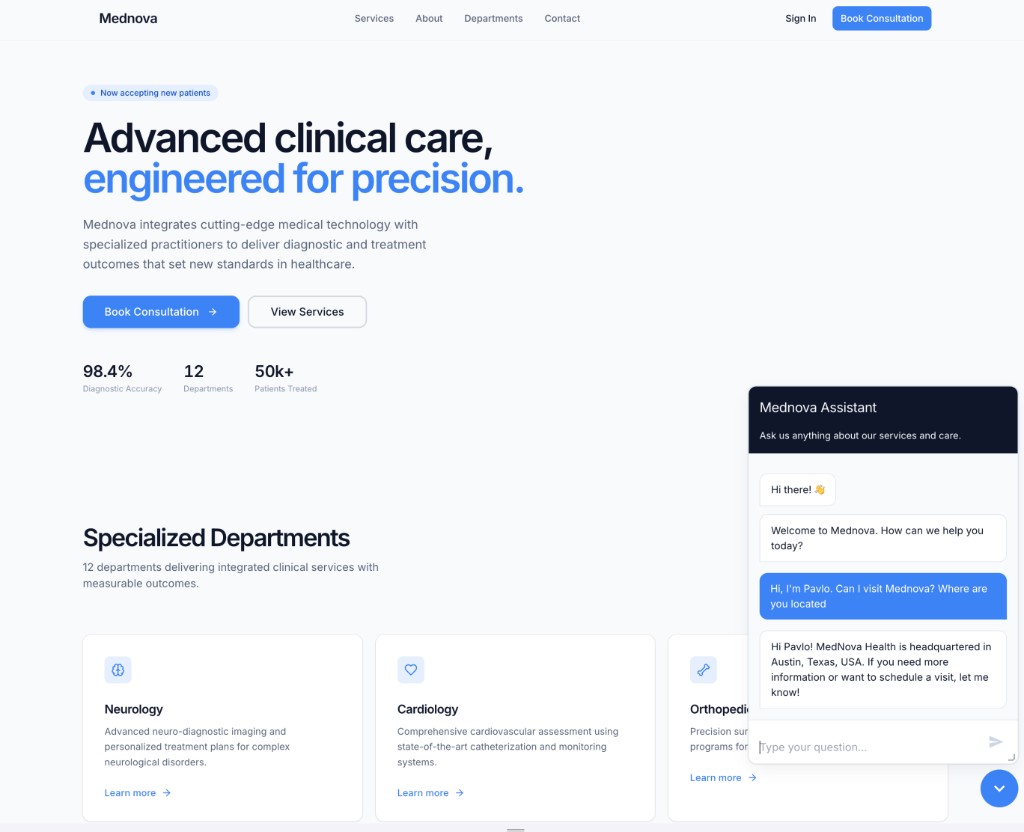
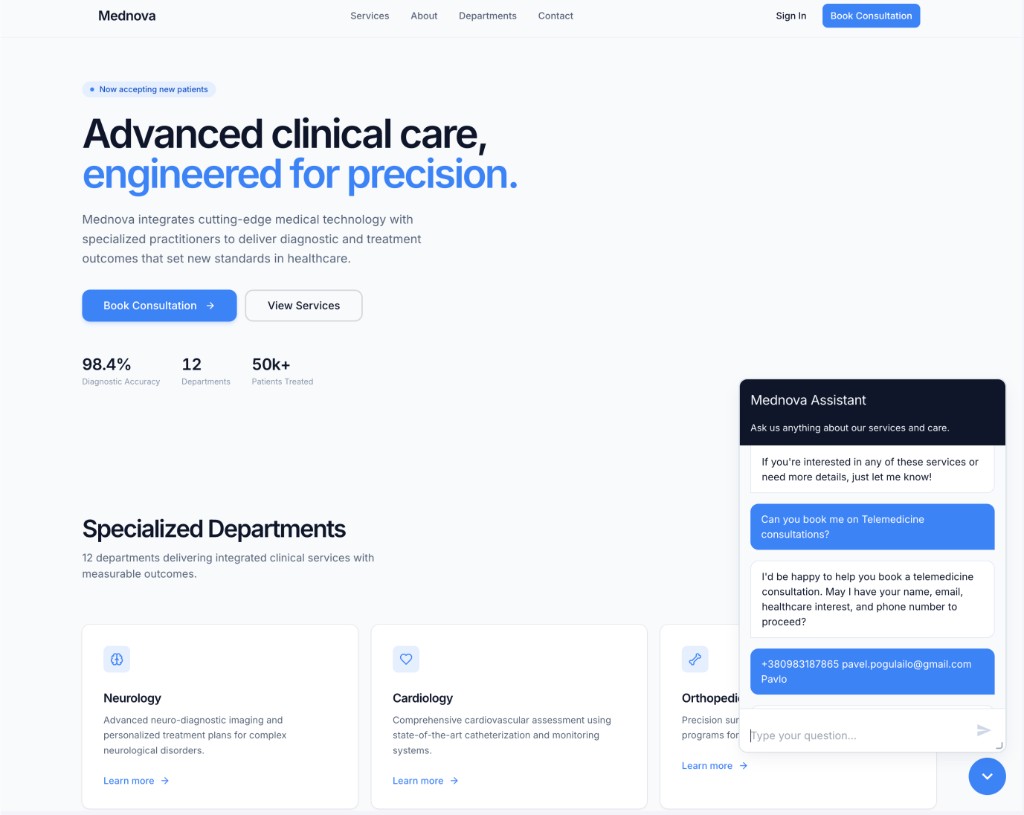
A chatbot that's actually grounded/
Generic LLMs hallucinate. This bot doesn't — every answer is retrieved from the client's own knowledge base, then composed by GPT against that retrieved context.
The goal was simple to write down and hard to do well: stand up a chatbot for Mednova that answers from their healthcare-domain knowledge base, logs every conversation for review, and is observable enough that the client can trust it before exposing it to end users.
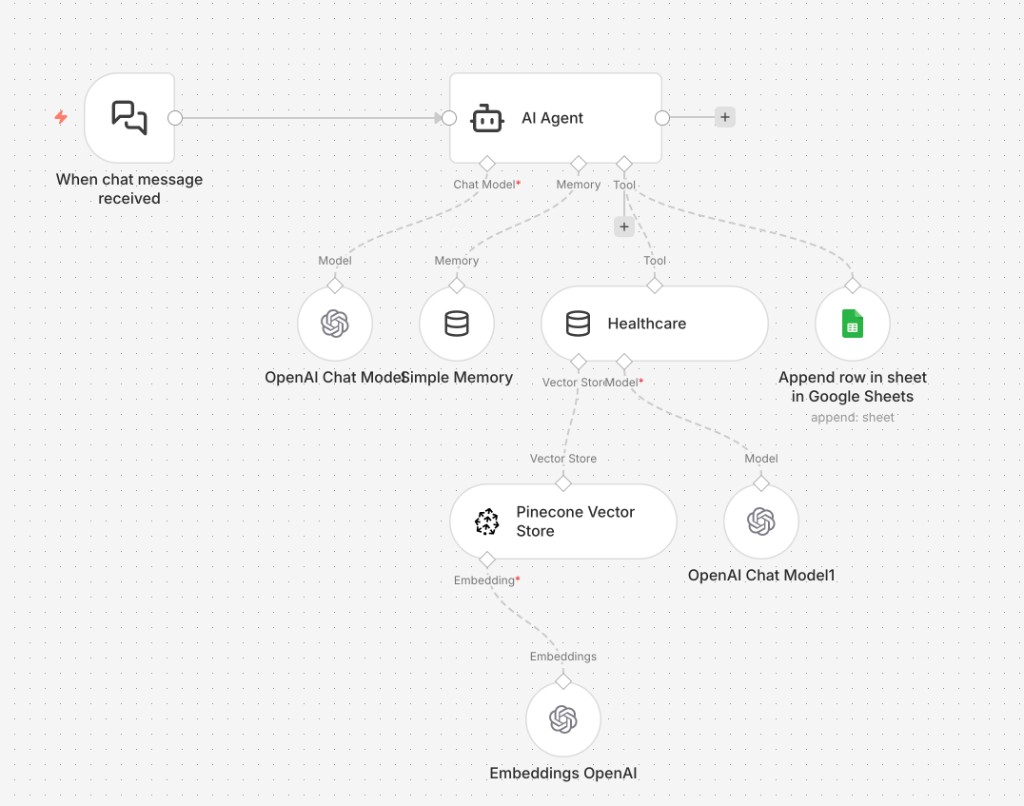
I built the whole pipeline in n8n: a chat trigger feeds an AI Agent node, which calls an OpenAI Chat Model for reasoning, pulls context from a Pinecone vector index seeded with the client's docs via OpenAI embeddings, and writes each turn into a Google Sheet for offline review. Simple Memory keeps short-term context per session.
The whole thing is self-hostable, costs cents per conversation, and lets the client iterate on prompts without touching code.
Chat trigger → AI Agent → Pinecone → reply/
The hot path is a single n8n workflow: incoming chat, embed query, search Pinecone, compose reply with retrieved context, log the turn. No code to deploy, no servers to babysit.
- Single n8n workflow per environment
- OpenAI embeddings on both ingest and query
- Pinecone namespace per knowledge domain
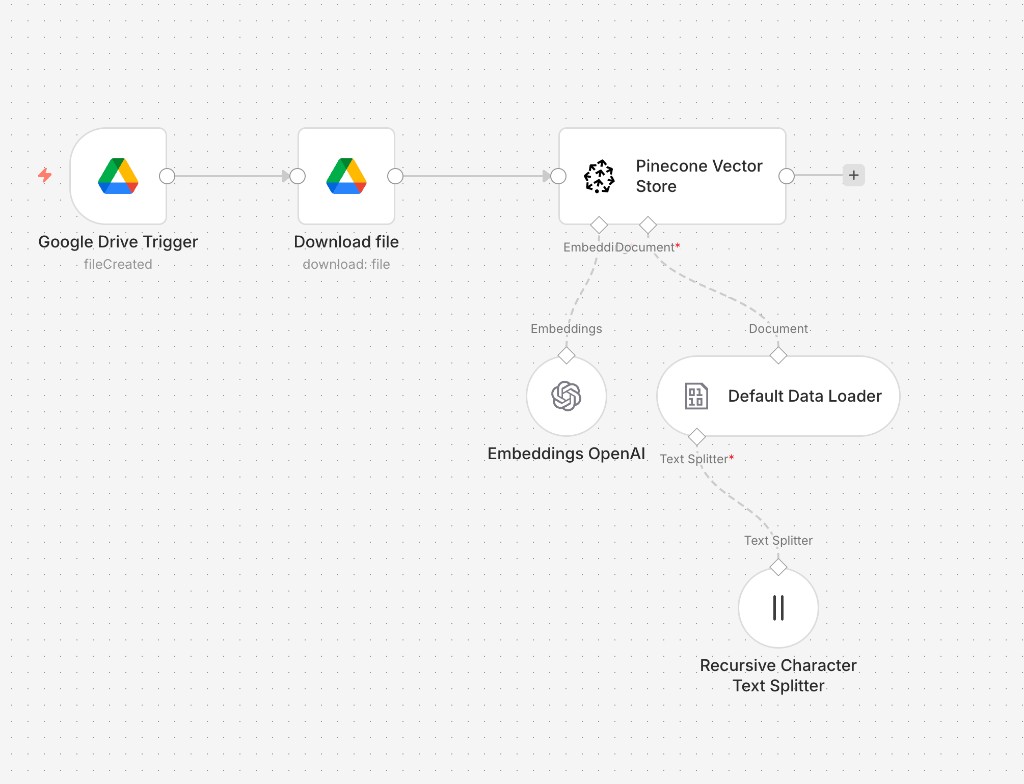
Healthcare docs, chunked and embedded once/
Source docs are chunked, embedded with OpenAI, and pushed into a Pinecone index. Re-ingest is idempotent — a doc rev re-embeds only that doc and replaces its vectors.
- Idempotent doc upserts by stable doc-id
- Chunking tuned for healthcare content density
- Per-doc tags for filtered retrieval at query time
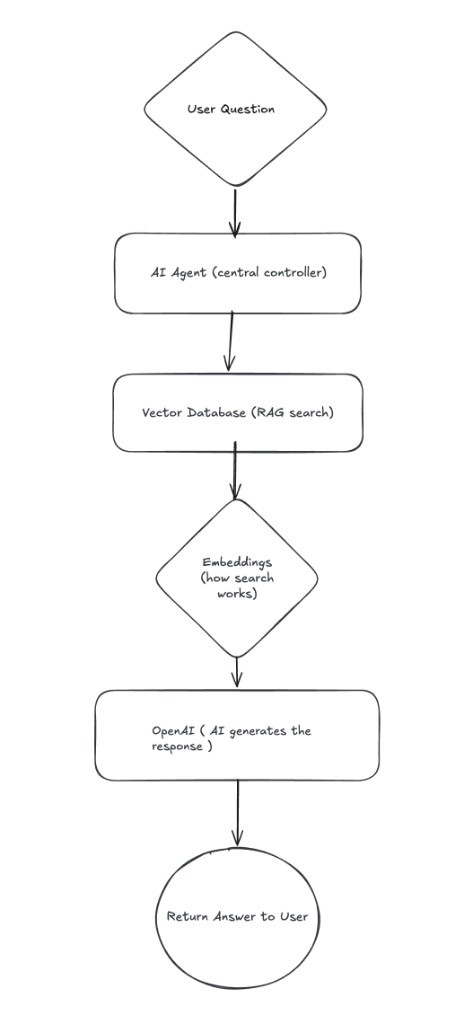
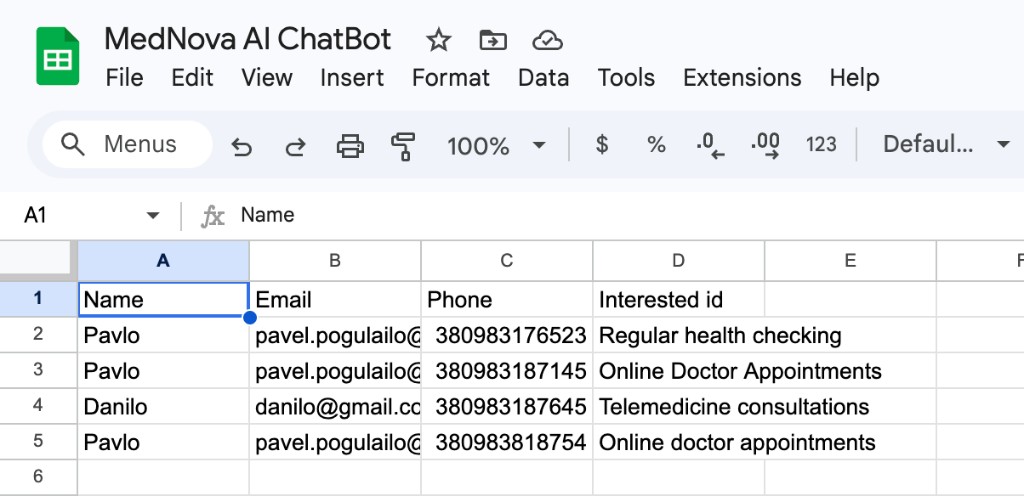
Every conversation logged for review/
Each turn — the question, the retrieved context, the LLM reply — is appended to a Google Sheet so the client can review answers, flag misses, and feed corrections back into the index.
- Per-turn audit row in Google Sheets
- Flagged-answer column drives reingestion
- Cheap, transparent, no extra UI to learn
From a question to a grounded answer/
A walk through the n8n workflow, the Pinecone vector store, the Sheets audit log, and the per-turn artifacts.
Ship a chatbot that doesn't hallucinate/
If you're considering a RAG chatbot for support, docs, or internal knowledge — I can help you scope, build, and de-risk the pipeline.